Como chegar ao Beto Carrero World distância das principais cidades.
História Beto Carrero. O paulista João Batista Sérgio Murad que passou 16 anos quase em tempo integral no papel do caubói fictício Beto Carrero o personagem central de um parque

História Beto Carrero. O paulista João Batista Sérgio Murad que passou 16 anos quase em tempo integral no papel do caubói fictício Beto Carrero o personagem central de um parque

Sua história é repleta de controvérsias. Teria sido ele realmente carpinteiro? Era mesmo um senhor idoso quando se casou com a jovem Maria? Por BBC. 25/12/2021 08h13 Atualizado há 2

A travessia de automóveis e pedestres entre São Sebastião e Ilhabela é realizada por meio de balsas que conectam a cidade continental de São Sebastião localizada no litoral norte do

Por Marie Declercq. 4.9.19. Partilhar. Tweet. Snap. Se você existe na internet alguma vez já se deparou com uma pessoa com atração por pés seja recebendo pedidos de um anônimo
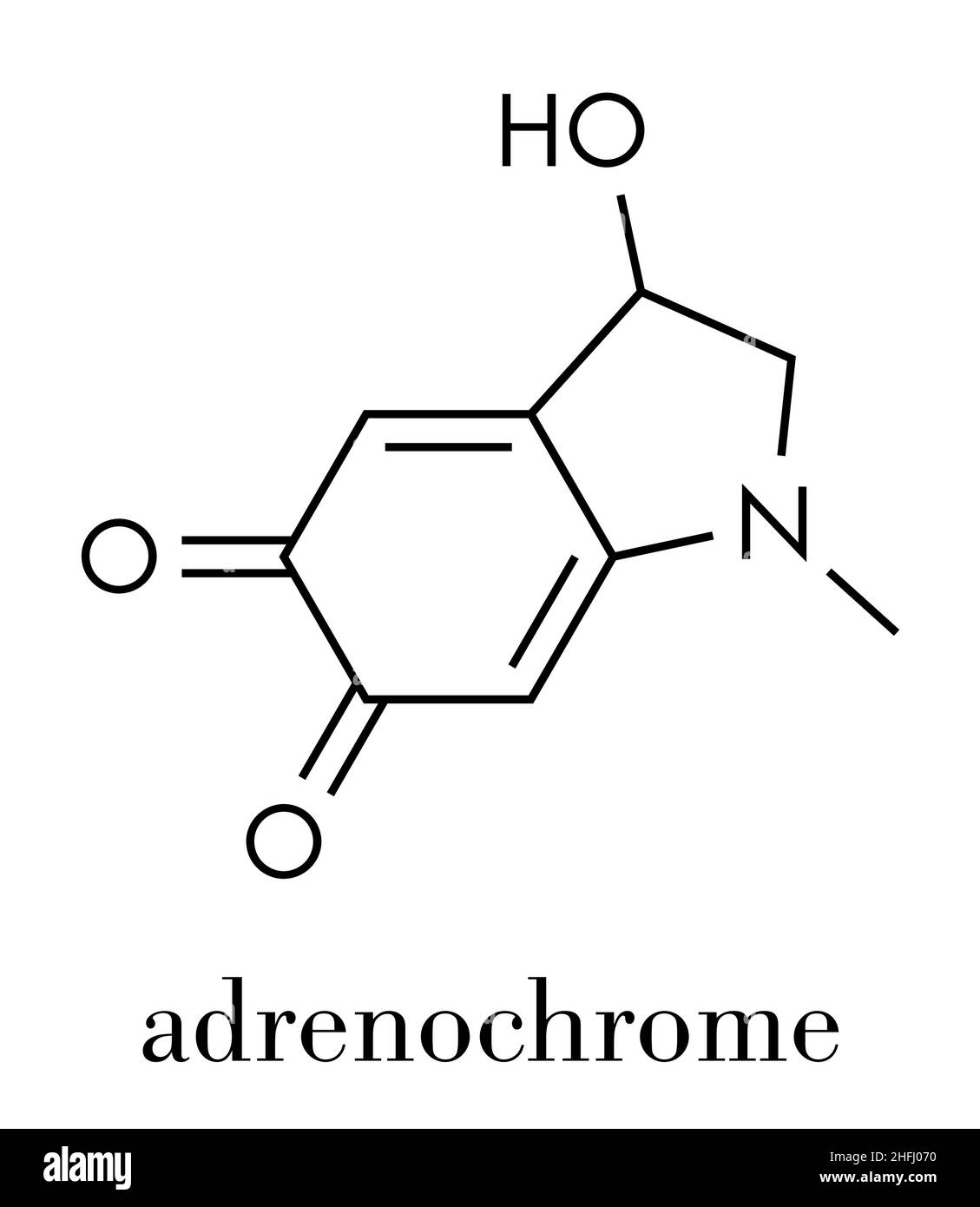
Objeto de teorias da conspiração o adrenocromo é derivado da adrenalina e tem usos limitados. O adrenocromo não é uma droga extraída de crianças torturadas como compartilhado em peças de.

italianoportatile. 122 posts · 2K followers. View more on Instagram. 57 likes. italianoportatile. Boa tarde! E você sabe como dizer boa tarde em italiano? Vamos lá descobrir ;-)! E se

São José do Ouro é uma cidade de Estado do Rio Grande do Sul. Os habitantes se chamam ourenses. O município se estende por 3348 km² e contava com 6
Além de toda a riqueza do mundo mágico o universo de Harry Potter também presenteou os fãs com personagens diferentes entre si que formam o núcleo principal dos filmes e
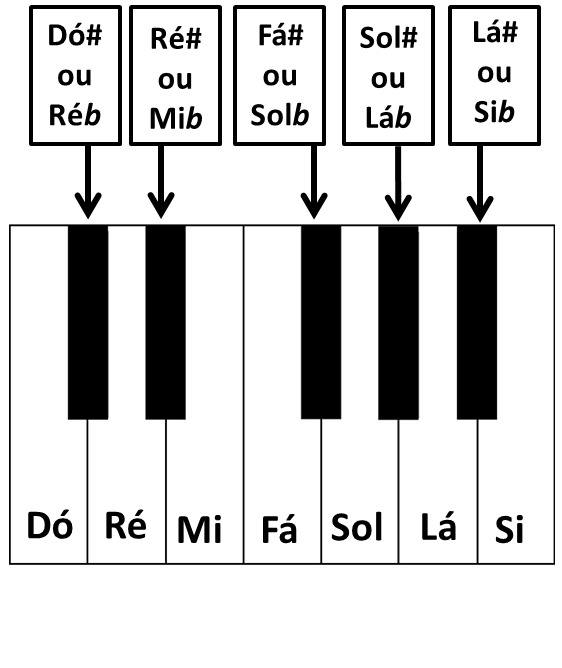
Em resumo existem 12 escalas musicais no teclado. Cada escala é formada por uma sequência específica de notas que podem variar de acordo com o tom e o estilo musical.